

Introduction
This notebook gives a practical guide to inspire developers and researchers in building AI applications. Through a hands-on example of creating a multimodal RAG (Retrieval Augmented Generation) system for scientific papers, we’ll explore: How to leverage Large Language Models (LLMs) hosted on Nscale serverless platform The fundamentals of building effective RAG systems While we’ll be building a specific implementation for processing arXiv papers, the concepts and patterns demonstrated here can be adapted to create various AI services and applications. Whether you’re looking to understand RAG systems, explore multimodal AI, or learn how to utilize Nscale’s hosted LLMs effectively, this notebook provides a foundation to build upon. You can access the Jupyter Notebook version here, where you can explore and execute the code yourself.Outlines of a simple RAG
If you are not familiar with RAG, it is a technique that enhances AI language models by first retrieving relevant information from a knowledge base, then using that context to generate more accurate and informed responses. Think of it as giving an AI model access to a specialized library that it can reference before answering questions. Here’s the outline of a simple RAG workflow:- Indexing phase:
- The user first uploads a document
- The document’s content is then split into chunks
- Those chunks are fed to an embedding model that will convert the text to a vector of number that captures the sementic meaning of the chunk
- The chunk is then stored in a vector store or database
- Retrieval phase:
- The user will query the system
- The query itself will be converted to an embedding
- A vector similarity search between the query vector and the vectors stored in the database then happens.
- Generation phase:
- Once the vectors are retrieved, we use a large language model to generate a response based on the query and the retrieved context.
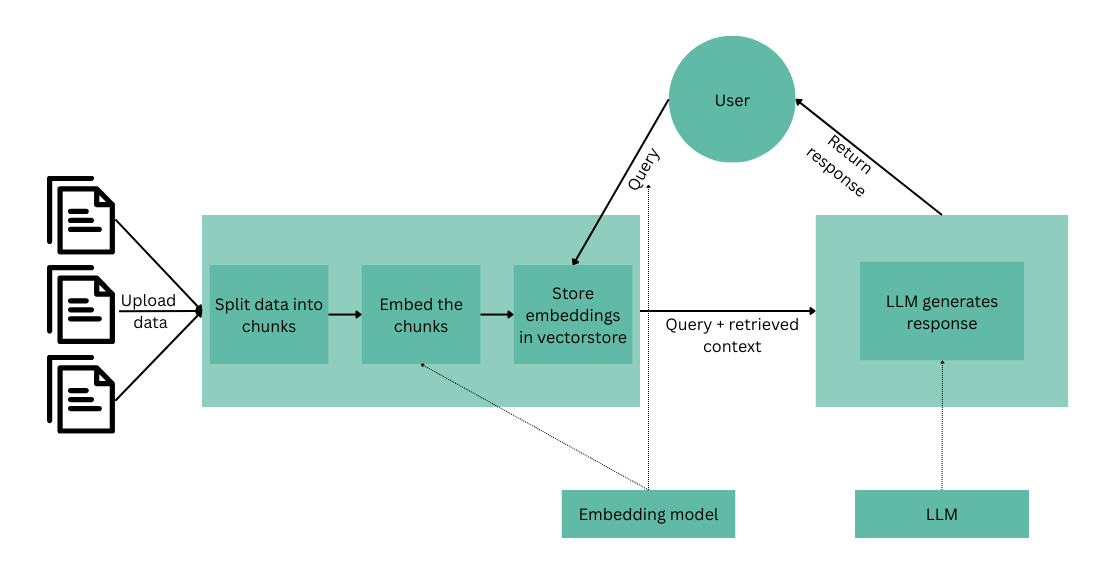
Multimodal RAG
While simple RAGs can work well, they often fall short in tasks that requires parsing complex layouts. For example scientific paper, are complex to parse because of their sometimes difficult structure which can include text, image and tabular data. One solution has been to leverage projects such as LlamaParse or unstructured.io to parse those documents using OCR, layout detection and captioning. Such approach can work well but will lead to overhead time in the indexing phase as seen in the following figure from ColPali: EFFICIENT DOCUMENT RETRIEVAL WITH VISION LANGUAGE MODELS by Faysse et al.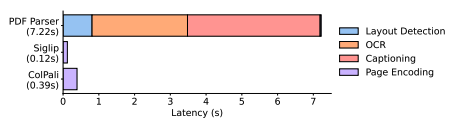
Implementation
Install the required libraries
Export the necessary variables
Retrieve the arXiv data
If you haven’t heard of arXiv, in brief it’s an open-access repository where researchers share preprints of scientific papers before formal peer review, primarily in fields like physics, mathematics, and computer science. For our use case we will use the paper “ColPali: EFFICIENT DOCUMENT RETRIEVAL WITH VISION LANGUAGE MODELS” by Faysse et al. And leverage arxiv’s API to retrieve the paper.Initialise the multimodal model
We are going to initialise ColPali model using the byaldi library. ColPali will be used to generate the embeddings of the document. It does so by converting the document into images that will then be cut into patches, these patches are later embedded in a 128 dimension vector space.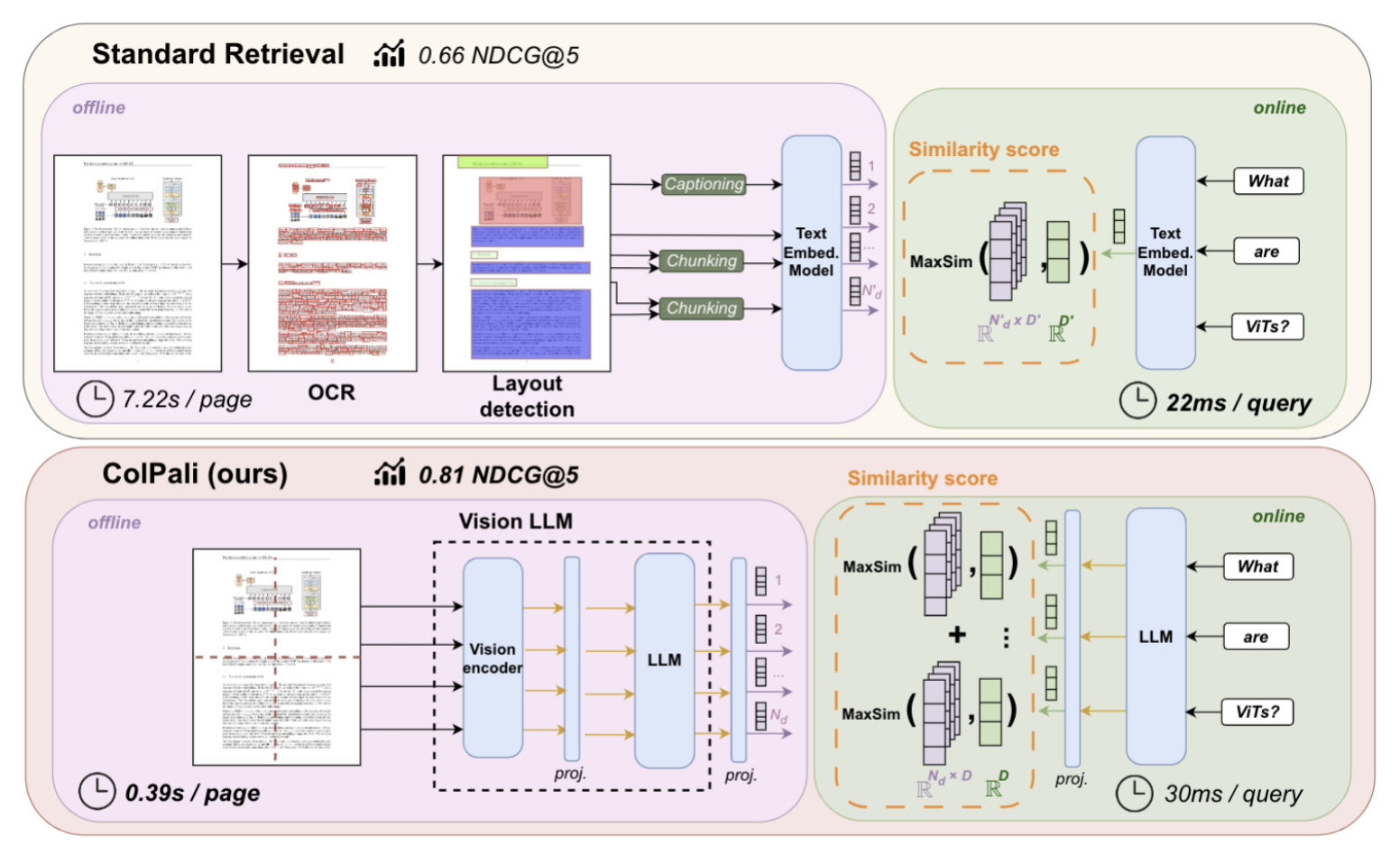
Indexing phase
Initialise LLM
We will use the new Llama 4 Scout as LLM, it is a 17 billion active parameter model with 16 experts that uses a mixture-of-experts (MoE) architecture. It’s a very powerful multimodal model with native multimodality, strong performance and an extremely large context window. Running such model locally is not feasiable. For this reason we will be inferencing the model through Nscale serverless! Nscale offers 5$ of free credit upon signup, way more than enough to fully understand the ColPali paper!Retrieval and generation phase
LLM output
The table presents results that compare various models and their performance across multiple metrics.Step 1: Identify the metrics and models presented
The table provides a comprehensive evaluation of baseline models and proposed methods on ViDoRe, with only visual elements and text-only metrics not computed for benchmarks.Step 2: Analyze the performance of different models
The models are evaluated based on various metrics such as ArxivQ, DocQ, InfoQ, TabF, TATQ, Shift, AI, Energy, Gov, Health, and Avg.3: Compare results across different models and methods
Results are presented using Recall@1 metrics.4: Conclusion
Based on the provided information, the description of table 2 results could not be found, however, table 6 and 7 results are provided.5: Results from Table 6 and Table 7
The best result in table 6 is from ColPali (+Lac Iter.) which scores 72.7 and has a recall of 85.0.
The best results in table 7 are from ColQwen2 (224) which scores 86.6 and 86.6 on Energy and Health.6: Final Conclusion
The description of table 2 results could not be found. However, based on the results from table 6 and 7, ColPali and ColQwen2 models tend to perform better across various metrics.
The table provides a comprehensive evaluation of baseline models and proposed methods on ViDoRe, with only visual elements and text-only metrics not computed for benchmarks.Step 2: Analyze the performance of different models
The models are evaluated based on various metrics such as ArxivQ, DocQ, InfoQ, TabF, TATQ, Shift, AI, Energy, Gov, Health, and Avg.3: Compare results across different models and methods
Results are presented using Recall@1 metrics.4: Conclusion
Based on the provided information, the description of table 2 results could not be found, however, table 6 and 7 results are provided.5: Results from Table 6 and Table 7
The best result in table 6 is from ColPali (+Lac Iter.) which scores 72.7 and has a recall of 85.0.
The best results in table 7 are from ColQwen2 (224) which scores 86.6 and 86.6 on Energy and Health.6: Final Conclusion
The description of table 2 results could not be found. However, based on the results from table 6 and 7, ColPali and ColQwen2 models tend to perform better across various metrics.
Conclusion
In this notebook, we’ve successfully built a multimodal RAG system for scientific papers that combines:- ColPali’s powerful document retrieval and embedding generation
- Llama 4 Scout’s advanced vision-language understanding, accessed through Nscale’s serverless platform
- Download and process arXiv papers
- Index documents using ColPali’s multimodal capabilities
- Perform intelligent retrieval based on user queries
- Generate contextual responses using Llama 4 Scout
What We’ve Learned
- How to implement a multimodal RAG system without complex OCR pipelines
- Ways to leverage Nscale’s LLMs effectively
- Techniques for handling both text and visual content in academic papers
Build Your Own
This implementation serves as a starting point - here are some ways you could extend it:- Adapt the system for other document types (patents, technical documentation, etc.)
- Add more sophisticated indexing, retrieval and generation strategies
- Implement concurrent processing for large document collections
- Create a web interface or API
- Fine-tune the models for your specific use case